1. 시작하면서
그래도 굉장히 빠르게 전 포스팅에 이어서 글을 작성하게 되었습니다! 이것보다 더 오래걸리면 분명 까먹는 부분들이 많을거고, 뭣보다 쿠버네티스에 여러 서비스를 배포한 결과에 대해서 꼭 한 번 정리해야했기에...
사실 ChatForYou 와 연동하기 위해 배포한 서비스는 굉장히 다양한 편입니다. 처음부터 '개발부터 배포까지' 라는 포부로 시작했기에 쿠버네티스를 설치하고 여기에 이것저것 작업하면서 진짜 생각나는대로 다 배포했거든요ㅋㅋㅋ그래서 당연하다면 당연하게도 점점 Ram 이나 CPU 사용률에 미친듯이 올라가는걸 보고 이거 안되겠다 싶었어요ㅠㅠ
특히 prometheus 와 이번 글에는 없지만 Jenkins, sonarqube 가 의외로 자원을 많이 잡아먹는다는 걸 알게되었습니다. 다행히 아직은 다중화 할 생각은 없어서 모든 서비스를 1개씩만 배포했지만, 추후 2~3 개씩 배포한다고 하면 인스턴스(자원)이 더 필요하지 않을까...? 라는 생각을 하게 되었습니다.
그렇게 openstack 으로 4cpu 8GB 를 갖는 인스턴스를 총 3개로 늘렸고, 1, 2 번 인스턴스는 일반 서비스 배포용으로 사용하고, 3번 인스턴스는 모니터링 서비스 배포용으로 사용하는 목적으로 구분하였습니다. 즉, prometheus 와 Grafana, Loki 는 모두 instance-3 에 배포되고 있습니다.


2. Promehteus Grafana Loki : 너희는 무엇이냐...?
Prometheus는 강력한 오픈 소스 모니터링 및 경고 시스템이다. 이는 시간에 따라 변화하는 데이터를 수집하고 저장하는데 주로 사용되며, 주로 시스템과 서비스의 실시간 모니터링과 경고 생성에 활용된다. Prometheus는 다양한 데이터 소스로부터 메트릭을 수집하는 '풀(Pull)' 모델을 사용하며, 간단한 구성으로 다양한 메트릭을 수집하고 처리할 수 있다. 또한, 강력한 쿼리 언어인 PromQL을 사용하여 복잡한 데이터 집계 및 분석이 가능하다(어려운 것은 덤이다).
Grafana는 이러한 메트릭 데이터를 시각화하고 분석하는 데에 최적화된 대시보드 및 그래프 도구입니다. Grafana는 Prometheus 는 물론 Loki, Elasticsearch 등 다양한 데이터 소스를 지원하며, 사용자가 쉽게 대시보드를 생성하고 사용자화할 수 있다. 이를 통해 시스템의 성능 지표를 한눈에 파악하고, 잠재적 문제를 신속하게 발견 가능하다. 이렇듯 Grafana의 유연성은 사용자가 복잡한 쿼리를 시각적으로 표현하고, 알람을 설정하여 시스템의 이상 징후에 즉시 대응할 수 있도록 돕는 도구이다
마지막으로, Loki는 Grafana Labs에서 개발한 로그 집계 시스템으로, Prometheus의 설계 철학을 기반으로 한다. 이 말인즉슨 Loki는 효율적인 저장과 검색을 위해 메트릭과 유사한 모델을 사용하여 로그 데이터를 처리한다는 의미이다. 또한 시계열 로그 데이터의 인덱싱에 메타데이터만을 사용하므로, 대량의 로그 데이터를 효율적으로 저장하고 관리할 수 있다. Loki는 Grafana와 긴밀하게 통합되어, 로그 데이터의 시각화 및 분석을 간편하게 할 수 있게 해준다.
3. Prometheus Grafana Loki : 서비스 선정과 그 이유
그래서 ELK 가 아닌 prometheus 와 garafana 그리고 Loki 인가? 에 대해서 먼저 설명하겠다.
ELK 는 물론 강력한 도구이다. 사실 이미 ELK 를 구축하고 사용해봤던 입장에서는 그 Elasitcsearch 검색기능의 강력함과 kibana 로 대표되는 시각화의 편리함 을 알기에 그냥 ELK 를 쓸까...? 하는 생각도 했었다. 그러나 아래 2가지 이유에서 ELK 보다는 이쪽이 더 적합하다고 판단되었다.
1. Prometheus 는 시계열 데이터를 수집, 저장, 처리하는 데 특화되어 있다. 이는 애플리케이션의 성능 지표(예: 서버 응답 시간, 시스템 자원 사용량)를 효과적으로 모니터링 할 수 있다는 의미이다. 특히 ChatForYou 처럼 실시간 성능 모니터링 - CPU 사용률, Memory 사용률, 네트워크 사용률 등 - 이 필요한 경우 ELK 보다는 Prometheus 가 더 적합하다고 판단되었다.
2. Loki 는 prometheus 와 마찬가지의 이유에서 선정했다. prometheus 와 마찬가지로 시계열 로깅에 적합하기 때문에 서비스에 대한 실시간 로깅이 가능하기도하고, 무엇보다 GrafanaLab 에서 개발한 만큼 Grafana 와 연동하기 좋기 때문이다.
3. Grafana 는 Kibaba 를 대체하는 시각화 도구로 다양한 데이터 소스와 연동이 가능하다는 점과 특정 이벤트에 대해서 경고와 알림이 가능하다는 점에 매우 좋아보였다. 추후 slack 와 연동하면 이벤트 발생 때마다 알림을 받을 수 있다면 '실시간 관리' 라는 점에서 정말 멋지게 동작할 수 있지않을까? 싶다.사실 ELK 기억도 잘 안나고 새로운 걸 만져보고 싶었다는 건 안비밀ㅋㅋㅋㅋ
3. 배포를 위한 기본 작업 : 데이터 저장은 NFS
쿠버네티스를 사용하면서 가장 고민했던 점이 무엇인가? 라고 묻는다면 두말하지 않고, "쿠버네티스에 배포한 파드들의 데이터 저장" 이라고 대답할 것이다. 쿠버네티스로 여러 서비스를 배포하는 것까지는 좋았는데 문제는 파드를 한 번 끄고 재시작하거나 디플로이먼트를 삭제하고 재배포라도 하는 경우라면 기존에 파드에서 사용했던/저장했던 정보가 싹! 날아가버렸다. 한번은 Jenkins 에 열심히 github 와 연동하고 이것저것 설정하고 다 했는데 껐다 켰더니 싹 날아가버렸던 사건이 있었다. 세상에...그날 하루종일 했던 모든 것들이 단 5초만에 날아간 것을 보고 있자니 정말....ㅠㅠ
그래서 궁금했던 것 같다. "쿠버네티스가 정말 좋은 기술이고 이곳저곳에서 많이 사용하는데 그렇다면 모든 사람들이 나처럼 한번 파드가 꺼지면 모든 것을 다시 설정할까? 서비스를 올리고 사용했던 데이터들, 특히 DB 를 쿠버네티스에 배포한다면 모든 데이터가 날아가다는 것인데 이게 맞을까...? 하고 말이다
당연히! 방법은 있었다. 하긴 오히려 방법이 없는게 이상한 거겠지. 그렇게 쿠버네티스를 공부하다가 알게된 것이 바로 storageclass, pv, pvc 의 개념이었다. 이 세가지는 쿠버네티스를 구성하는 데이터 저장과 관련된 주요 개념중 하나이다.
StorageClass: StorageClass는 쿠버네티스에서 다양한 스토리지 타입을 추상화하는 방법을 제공한다. 이를 통해 사용자는 스토리지의 실제 구현 세부사항을 신경 쓰지 않고도 필요한 스토리지 유형을 요청할 수 있다.
사용 사례: 예를 들어, 클라우드 제공자의 SSD 기반 스토리지나 로컬 환경의 NFS 서버 등 다양한 백엔드 스토리지를 정의할 수 있다.
Persistent Volume (PV): PV는 클러스터 내에서 관리자가 프로비저닝한 스토리지의 한 조각이다. 이는 노드의 물리적 스토리지(예: 하드 디스크, NFS, iSCSI)를 나타냅니다.
특징: PV는 클러스터 리소스처럼 사용되는데 관리자는 여러 PV를 생성하여 클러스터 내에서 사용할 수 있는 스토리지 풀을 만들 수 있다.
Persistent Volume Claim (PVC): PVC는 사용자가 PV에 대해 요청하는 방식으로 사용자는 PVC를 통해 필요한 스토리지의 크기와 접근 모드를 명시한다.
연결 방식: 쿠버네티스는 PVC를 만족시킬 수 있는 PV를 자동으로 찾아 연결한다. 이 과정은 동적(자동 프로비저닝) 또는 정적(미리 생성된 PV 사용)으로 2가지의 방법이 있다.
즉 PV 와 PVC 를 이용해서 쿠버네티스에 배포되는 서비스의 스토리지를 물리적인 스토리지로 잡아놓고 추후에도 계속 그곳을 바라보게 한다면...? 디플로이먼트가 재배포되어도, 파드가 삭제되어도 심지어 쿠버네티스 시스템 자체가 종료되고 다시 시작되더라도 이전에 사용하던 스토리지를, 데이터를 계속 사용 할 수 있는 것이다. 나는 PV 를 특정 서버에 NFS 를 설치후 해당 서버의 NFS 로 공유되는 디렉토리를 사용하게 만들었다.
StorageClass는 다양한 스토리지 타입을 추상화하여 사용자가 스토리지의 세부 구현을 신경 쓰지 않고 필요한 유형을 요청할 수 있게 해주고, Persistent Volume (PV)는 관리자가 프로비저닝한 클러스터 내 스토리지 조각이며, Persistent Volume Claim (PVC)는 사용자가 필요한 스토리지 크기와 접근 모드를 명시하여 PV에 요청하는 방식이다.
4. Prometheus 배포와 설정
1) prometheus.yaml
- prometheus 를 배포하기 위한 yaml 이다.
- 전체적인 설정이 모두 담겨있고, 가장 주의해서 살펴보아야하는 것은 위에서 설명한 pv, pvc 부분과 ClusterRoleBinding 부분으로 여기가 제대로 설정되지 않으면 ChatForYou 와 같은 내가 직접배포하는 서비스에 대해서는 데이터 수집이 가능하더라도 쿠버네티스 모니터링에 필요한 apiserver, cadvisor, endpoints 등에 대해서는 수집이 안되기 때문에 쿠버네티스 모니터링을 위해서는 꼭 설정해주어야한다.
- 또한 deployment 에서 nodeselector 도 꼭 살펴보자. 이 설정은 쿠버네티스에 해당 서비스를 배포 시 특정 노드에 배포되도록 하는 설정이다. 즉 이 설정을 통해 promehteus 는 openstack-instance-3 에 항상 배포되게 된다.
# Namespace 정의:
# 'monitoringsystem'이라는 이름의 네임스페이스를 생성합니다.
# 이 네임스페이스는 Prometheus 관련 모든 리소스를 격리하여 관리하기 위한 것입니다.
apiVersion: v1
kind: Namespace
metadata:
name: monitoringsystem
---
# StorageClass 정의:
# 'nfs-storage'라는 이름의 NFS 기반 스토리지 클래스를 정의합니다.
# 이 클래스는 볼륨 프로비저닝을 'kubernetes.io/no-provisioner'로 설정하여 자동 프로비저닝을 사용하지 않습니다.
# 'WaitForFirstConsumer' 모드는 볼륨 바인딩을 PVC가 사용될 때까지 지연시킵니다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
namespace: monitoringsystem
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
# PersistentVolume 정의:
# 'prometheus-pv'라는 이름의 PersistentVolume(PV)을 정의합니다.
# 이 PV는 NFS 서버에서 제공되며, 10Gi의 스토리지 용량을 가집니다.
# 'ReadWriteOnce' 액세스 모드는 볼륨을 단일 노드에서 읽기/쓰기로 사용할 수 있음을 의미합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-pv
namespace: monitoringsystem
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
storageClassName: nfs-storage
nfs:
server: [NFS_SERVER_IP] # NFS 서버의 IP 주소입니다.
path: /nfs-data/prometheus # NFS 서버 상의 데이터 경로입니다.
---
# PersistentVolumeClaim 정의:
# 'prometheus-pvc'라는 이름의 PersistentVolumeClaim(PVC)을 정의합니다.
# 이 PVC는 위에서 정의한 'prometheus-pv' PV에 대한 클레임을 생성합니다.
# PVC는 10Gi의 스토리지를 요청하며, 'ReadWriteOnce' 액세스 모드를 사용합니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-pvc
namespace: monitoringsystem
spec:
accessModes:
- ReadWriteOnce
storageClassName: nfs-storage
resources:
requests:
storage: 10Gi
---
# Deployment 정의:
# 'prometheus-deployment'라는 이름의 Deployment를 정의합니다.
# 이 Deployment는 Prometheus 서버의 인스턴스를 관리합니다.
# Deployment는 1개의 복제본(replica)을 갖습니다.
# 'app: prometheus-server' 레이블을 사용하여 Pod를 선택합니다.
# 컨테이너는 'prom/prometheus:latest' 이미지를 사용하며, Prometheus 구성 파일과 데이터 저장 경로를 설정합니다.
# 9090 포트를 통해 Prometheus 서버에 접근합니다.
# 두 개의 볼륨을 마운트합니다: 하나는 Prometheus 구성을 위한 ConfigMap, 다른 하나는 데이터 저장을 위한 PVC입니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoringsystem
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-server
template:
metadata:
labels:
app: prometheus-server
spec:
containers:
- name: prometheus
image: prom/prometheus:latest
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus/"
ports:
- containerPort: 9090
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus
volumes:
- name: prometheus-config-volume
configMap:
name: prometheus-config
- name: prometheus-storage-volume
persistentVolumeClaim:
claimName: prometheus-pvc
nodeSelector:
kubernetes.io/hostname: openstack-instance-3
---
# Service 정의:
# 'prometheus-service'라는 이름의 Service를 정의합니다.
# 이 서비스는 'app: prometheus-server' 레이블을 가진 Pod를 대상으로 합니다.
# NodePort 서비스 타입을 사용하여, 클러스터 외부에서도 30900 포트를 통해 Prometheus 서버에 접근할 수 있습니다.
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoringsystem
spec:
selector:
app: prometheus-server
type: NodePort
ports:
- protocol: TCP
port: 9090
targetPort: 9090
nodePort: 30900 # NodePort 번호입니다. 필요에 따라 변경할 수 있습니다.
---
# ClusterRole 정의:
# 'node-watcher'라는 이름의 ClusterRole을 정의합니다.
# 이 역할은 노드, 서비스, 엔드포인트, 파드 등의 리소스에 대한 'get', 'list', 'watch' 권한을 부여합니다.
# 또한, Ingress 리소스와 '/metrics' 경로에 대한 접근 권한도 부여합니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: node-watcher
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
# ClusterRoleBinding 정의:
# 'prometheus-node-watcher'라는 이름의 ClusterRoleBinding을 정의합니다.
# 이 Binding은 'node-watcher' ClusterRole을 'monitoringsystem' 네임스페이스의 'default' 서비스 계정과 연결합니다.
# 이를 통해 Prometheus 서버가 필요한 권한을 갖고 클러스터 리소스를 모니터링할 수 있게 됩니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-node-watcher
subjects:
- kind: ServiceAccount
name: default
namespace: monitoringsystem
roleRef:
kind: ClusterRole
name: node-watcher
apiGroup: rbac.authorization.k8s.io
2) configmap.yaml
prometheus 가 데이터를 '언제' '무엇을' '어떤 방법으로' 수집할 것인지 설정(config) 하는 map 이다. 여기서는 말 그대로 얼마의 시간을 두고 데이터를 수집하는지, 무엇을 수집하는지, 어떤 방법으로 수집하는지 - 수집 규칙, 레이블 설정 규칙 - 을 정의한다.
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config # ConfigMap의 이름입니다.
namespace: monitoringsystem # 이 ConfigMap이 속할 네임스페이스입니다.
data:
prometheus.yml: | # 이 아래는 prometheus.yml 파일의 내용입니다.
global:
scrape_interval: 15s # Prometheus가 타겟을 스크레이핑하는 간격입니다. 여기서는 15초로 설정되어 있습니다.
evaluation_interval: 15s # 규칙을 평가하는 간격입니다. 이것도 15초로 설정됩니다.
# 아래는 다양한 스크레이핑 타겟(또는 작업)을 정의합니다.
scrape_configs:
# 첫 번째 작업: 쿠버네티스 API 서버를 스크레이핑합니다.
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs: # 쿠버네티스 서비스 발견 설정입니다.
- role: endpoints
scheme: https # 스크레이핑할 때 HTTPS를 사용합니다.
tls_config: # TLS 설정입니다.
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # CA 인증서 파일의 경로입니다.
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 베어러 토큰 파일의 경로입니다.
relabel_configs: # 레이블 재설정 규칙입니다.
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
# 두 번째 작업: 쿠버네티스 노드의 메트릭스를 스크레이핑합니다.
- job_name: 'kubernetes-nodes-metrics'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
# 세 번째 작업: 쿠버네티스 파드의 메트릭스를 스크레이핑합니다.
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# ... 이하 내용 생략 ...
# 네 번째 작업: 쿠버네티스 서비스 엔드포인트의 메트릭스를 스크레이핑합니다.
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
# ... 이하 내용 생략 ...
# 다섯 번째 작업: 쿠버네티스 노드의 cAdvisor 메트릭스를 스크레이핑합니다.
- job_name: kubernetes-nodes-cadvisor
scrape_interval: 10s
scrape_timeout: 10s
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
# ... 이하 내용 생략 ...
# 여섯 번째 작업: 사용자 정의 타겟 'ChatForYou'를 스크레이핑합니다.
- job_name: 'ChatForYou'
kubernetes_sd_configs:
- role: pod
static_configs:
- targets: ['192.168.0.165:30443']
metrics_path: '/actuator/prometheus'
scheme: https
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app]
action: keep
regex: chatforyou-v03
tls_config:
insecure_skip_verify: true

5. Grafana 배포 및 설정
- 다음은 Grafana 에 대한 배포 및 설정!!
- Grafana 는 따로 configmap 은 필요없고, 배포하기위한 yaml 만 잘 작성해주면 된다. yaml 의 내용은 사실상 promehteus 와 거의 동일하다.
- 참고로 Grafana 의 초기 비밀번호는 admin/admin 이다.
# Namespace 정의:
# 'monitoringsystem'이라는 이름의 네임스페이스를 생성합니다.
# 이 네임스페이스는 Grafana 관련 모든 리소스를 격리하여 관리하기 위한 것입니다.
apiVersion: v1
kind: Namespace
metadata:
name: monitoringsystem
---
# StorageClass 정의:
# 'nfs-storage-grafana'라는 이름의 NFS 기반 스토리지 클래스를 정의합니다.
# 이 클래스는 볼륨 프로비저닝을 'kubernetes.io/no-provisioner'로 설정하여 자동 프로비저닝을 사용하지 않습니다.
# 'WaitForFirstConsumer' 모드는 볼륨 바인딩을 PVC가 사용될 때까지 지연시킵니다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage-grafana
namespace: monitoringsystem
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
# PersistentVolume 정의:
# 'grafana-pv'라는 이름의 PersistentVolume(PV)을 정의합니다.
# 이 PV는 NFS 서버에서 제공되며, 10Gi의 스토리지 용량을 가집니다.
# 'ReadWriteOnce' 액세스 모드는 볼륨을 단일 노드에서 읽기/쓰기로 사용할 수 있음을 의미합니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-pv
namespace: monitoringsystem
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
storageClassName: nfs-storage-grafana
nfs:
server: NFS_SERVER_IP # NFS 서버의 IP 주소입니다.
path: /nfs-data/grafana # NFS 서버 상의 데이터 경로입니다.
---
# PersistentVolumeClaim 정의:
# 'grafana-pvc'라는 이름의 PersistentVolumeClaim(PVC)을 정의합니다.
# 이 PVC는 위에서 정의한 'grafana-pv' PV에 대한 클레임을 생성합니다.
# PVC는 10Gi의 스토리지를 요청하며, 'ReadWriteOnce' 액세스 모드를 사용합니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoringsystem
spec:
accessModes:
- ReadWriteOnce
storageClassName: nfs-storage-grafana
resources:
requests:
storage: 10Gi
---
# ConfigMap 정의:
# Grafana의 데이터 소스 구성을 정의하는 ConfigMap 'grafana-datasources'를 정의합니다.
# 여기에는 Prometheus 데이터 소스의 구성이 포함됩니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-datasources
namespace: monitoringsystem
data:
datasources.yaml: |
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://prometheus-service.monitoringsystem.svc.cluster.local:9090 # Prometheus 서비스의 URL입니다.
isDefault: true
---
# Deployment 정의:
# 'grafana-deployment'라는 이름의 Deployment를 정의합니다.
# 이 Deployment는 Grafana 서버의 인스턴스를 관리합니다.
# Deployment는 1개의 복제본(replica)을 갖습니다.
# 'app: grafana-server' 레이블을 사용하여 Pod를 선택합니다.
# 컨테이너는 'grafana/grafana:latest' 이미지를 사용하며, Grafana 서버는 3000 포트에서 실행됩니다.
# 두 개의 볼륨을 마운트합니다: 하나는 Grafana의 데이터 저장을 위한 PVC, 다른 하나는 Grafana의 데이터 소스 구성을 위한 ConfigMap입니다.
# dnsConfig를 통해 사용할 DNS 서버를 지정합니다.
# nodeSelector를 사용해 특정 노드(여기서는 'openstack-instance-3')에만 이 Deployment가 배치되도록 합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-deployment
namespace: monitoringsystem
spec:
replicas: 1
selector:
matchLabels:
app: grafana-server
template:
metadata:
labels:
app: grafana-server
spec:
containers:
- name: grafana
image: grafana/grafana:latest
ports:
- containerPort: 3000
volumeMounts:
- name: grafana-storage-volume
mountPath: /var/lib/grafana
- name: grafana-datasources-volume
mountPath: /etc/grafana/provisioning/datasources
volumes:
- name: grafana-storage-volume
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources-volume
configMap:
name: grafana-datasources
dnsConfig:
nameservers:
- "8.8.8.8"
- "8.8.4.4"
nodeSelector:
kubernetes.io/hostname: openstack-instance-3
---
# Service 정의:
# 'grafana-service'라는 이름의 Service를 정의합니다.
# 이 서비스는 'app: grafana-server' 레이블을 가진 Pod를 대상으로 합니다.
# NodePort 서비스 타입을 사용하여, 클러스터 외부에서도 30901 포트를 통해 Grafana 서버에 접근할 수 있습니다.
apiVersion: v1
kind: Service
metadata:
name: grafana-service
namespace: monitoringsystem
spec:
selector:
app: grafana-server
type: NodePort
ports:
- protocol: TCP
port: 3000
targetPort: 3000
nodePort: 30901 # NodePort 번호입니다. 필요에 따라 변경할 수 있습니다.
6. Loki 배포
- Loki 도 마찬가지로 yaml 을 작성해서 배포한다.
- Loki 에 대해서는 사실 yaml 말고 크게 할 이야기가 없는데...loki 를 배포한 이유는 애초에 chatforyou 앱과 연동해서 해당 로그를 수집, 분석 하기 위한 도구로서 사용할 예정이다. 그러나 현재로서는 일단 배포만하고 chatforyou 와 어떠한 연동도 하지 않고 있기 때문에 일단 배포를 위한 yaml 에 대해서만 적어두고 추후 더 이야기하도록 하겠다.
apiVersion: v1
kind: Namespace
metadata:
name: monitoringsystem
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-loki
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: Immediate
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: loki-pv
namespace: monitoringsystem
spec:
storageClassName: nfs-loki
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.0.59
path: "/nfs-data/loki"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: loki-pvc
namespace: monitoringsystem
spec:
storageClassName: nfs-loki
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: loki-deployment
namespace: monitoringsystem
spec:
replicas: 1
selector:
matchLabels:
app: loki
template:
metadata:
labels:
app: loki
spec:
containers:
- name: loki
image: grafana/loki:latest # Use the appropriate Loki image
ports:
- containerPort: 3100
volumeMounts:
- name: loki-storage
mountPath: /var/loki
volumes:
- name: loki-storage
persistentVolumeClaim:
claimName: loki-pvc
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
- 8.8.4.4
nodeSelector:
kubernetes.io/hostname: openstack-instance-3
---
apiVersion: v1
kind: Service
metadata:
name: loki-service
namespace: monitoringsystem
spec:
type: NodePort
ports:
- port: 3100
targetPort: 3100
nodePort: 31000
selector:
app: loki
7. Grafana - Prometheus 연동
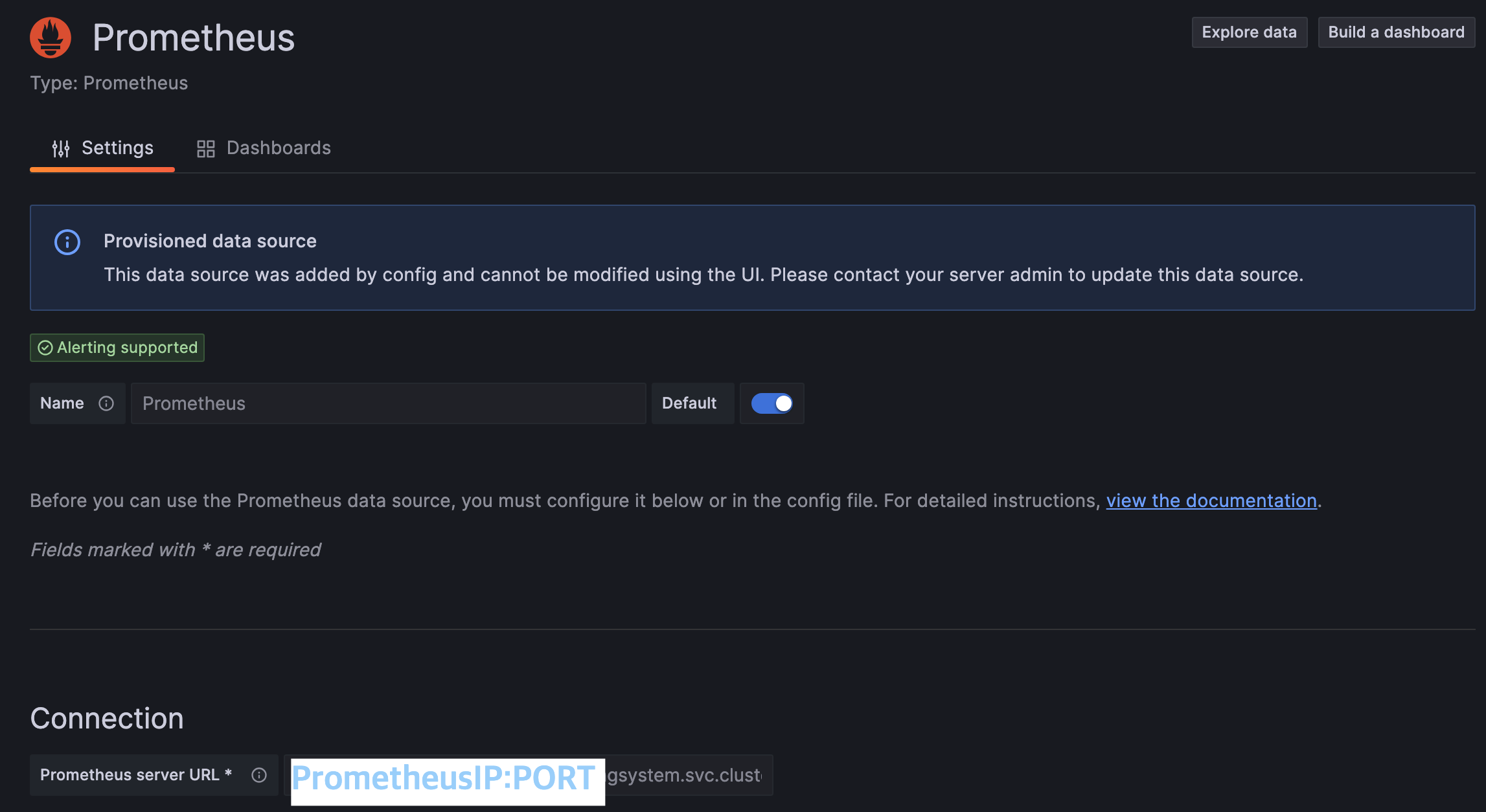
1) Proemtheus 와 Grafana 가 모두 배포가 완료되고 접속 가능하게 되었다면 Data sources 에 들어간다.

2) 이후 add new Data source 를 누르고 prometheus 를 선택한다.

3) 그리고 Connection 에 prometheusIP:PORT 를 적어준다. 이때 ip 는 당연히 nodeip 대신 kubernetes 의 container 를 적어주어도 무방하다. 웃긴것은 나의 경우 Grafana 가 바로 prometheus 를 인식?해서 따로 설정할 필요없이 바로 연결되었다는 점이다. 아마 같은 노드에 배포해서 그런건가 싶기도하고...
7. Grafana Dashboard 연동
1) Dashboard 탭으로 들어가서 New -> New Dashboard 를 클릭한다.

2) Dashboard 유형을 선택한다. 직접 만들기, 이미 만들어진 library 에서 가져오기, 다른 사람이 만든 dashboard 임포트하기가 있다. 처음 만드는 사용자의 경우 Import a dashboard 를 강력 추천한다.
이는 2가지 이유에서인데 첫번째로 promeQL 을 모르는 상황에서 바로 promeQL 을 작성해서 내가 원하는 대시보드를 만들어내는 것은 결코 쉬운 난이도는 아니라고 생각한다. 두번째는 다른 사람들이 Gafana 와 Prometheus 를 어떻게 사용하는지 알 수 있다는 점이다. 또한 이 두가지말고도 loki 나 elasticsearch 등과 어떻게 연계해서 대시보드를 만들 수 있는지 역시 알 수 있다. 여튼 그런 의미에서 import a dashboard 를 누르자

3) dashboard 선택 및 임포트
아래의 사이트에 접속해서 적당해보이는 springboot 대시보드를 선택한다. 당연하게도 그 대시보드를 그대로! 사용하는 것은 아니고 결국 조금씩 커스텀해야하기에 적당히 괜찮아보이는 것으로 import 해오자
https://grafana.com/grafana/dashboards/
Dashboards | Grafana Labs
Thank you! Your message has been received!
grafana.com
임포트는 총 2가지 방법이 있는데 첫째는 JSON 파일을 업로드 하는 것과 둘째는 ID 를 입력해서 Grafana 에서 해당 대시보드를 받아오는 방법이 있다.
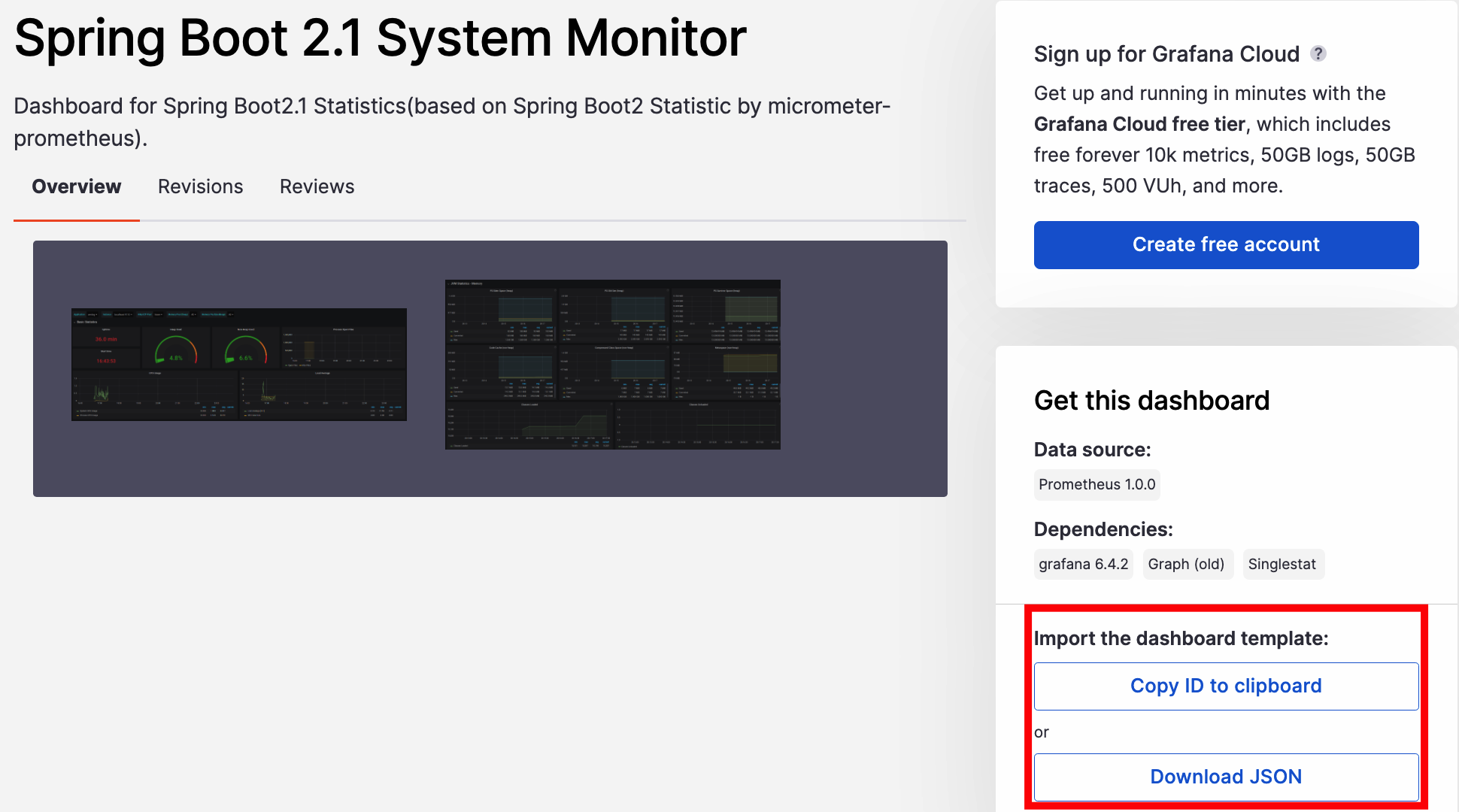
예를들어 SpringBoot 2.1 System Moniotr 대시보드를 선택했다면 아래에서 Copy ID 하거나 Download JSON 을 해서 임포트하자!
4) 대시보드 확인!
그렇게 대시보드를 임포트하고 나서 대시보드에 들어가게되면 높은 확률로 아래 2가지 상황이 나오게 된다.
첫번째는 모든 패널에 빨간색 ! 가 달려있거나 아니면 나처럼 바로 대부분의 컴포넌트들이 정상동작을 하며 이쁜 데이터를 보여주게 된다.
문제는 첫번째의 경우인데, 만약 패널에 ! 가 달려있다면 이걸 해결할 수 있는 건 결국 본인밖에 없다ㅠㅠ 어쩌면 당연한 이야기지만 각 패널에서 ! 가 나타난다는 것은 패널에 필요한 '뭔가'가 부족하거나 잘못되었기 때문인데 결국 이 부분은 로그를 어떤 문제가 있는지 확인하면서 해결해야한다.

8. Grafana 에서 GeoMap 사용해서 위치 찍어보기
오늘 포스팅의 메인 주제인 Grafana 에서 GeoMap 을 사용해서 접속하는 사람들의 위치를 GeoMap 에 찍어보자!
1) 대시보드에서 Add 를 눌러서 GeoMap 패널을 추가하자!

2) 스프링 부트에서 접속하는 클라이언트 정보를 저장한 메트릭스인 access_client_info_total 를 가져온다. 메트릭은 rdb 로 생각하자면 일종의 테이블이라고 생각하면 쉽다. 다만 이렇게만 데이터를 가져와서 Run queries 를 누르면 당연히 에러가 난다. 왜냐하면 해당 메트릭스에는 위도 경도 데이터 뿐만 아니라 각종 다른 데이터가 같이 들어있기 때문이다.
사실 RDB 의 경우에는 이렇게 모두 가져와도 쿼리로 이렇게 저렇게 해서 뽑아내면 내가 원하는 데이터를 뽑을 수 있긴하다. 다만 Prometheus 는 조금 다르다. 물론 이쪽도 쿼리로 뽑아올 수 있겠지만....이번에는 Grafana 에서 지원하는 기능을 사용해서 내가 원하는 데이터를 뽑아볼까 한다.
3) 바로 Transform data 라는 기능인데 이 기능은 Grafana 을 통해서 쿼리문에서의 where, group by, join, sort 를 기능으로 대체해서 사용할 수 있다. 예를 들어 아무런 행위 없이 단순히 'access_client_info_total' 이라는 메트릭의 정보를 가져오면 아래와 같이 나온다.
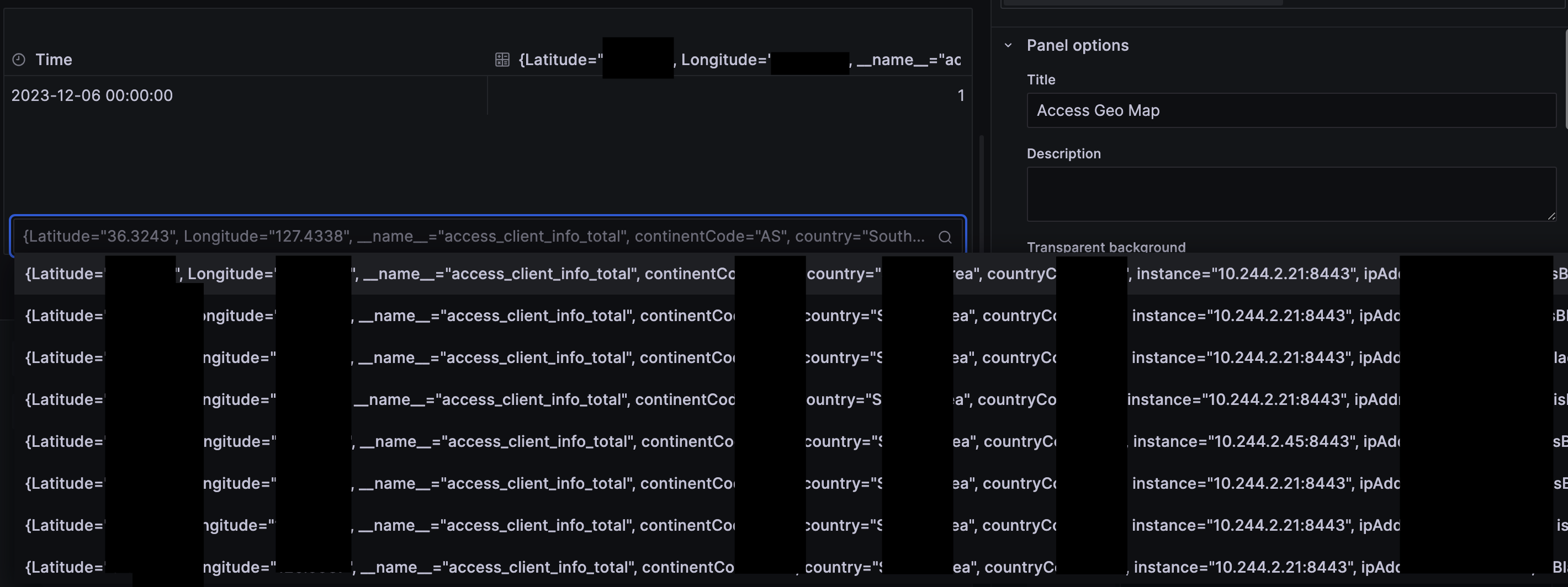
여기서 Transform data 중 Time series to table transform 와 Filter by name 을 사용해보았다.
Time series to table transform : prometheus 의 시계열 데이터는 기본적으로 시간 축을 따라 값이 배열된 형태이다. 이때 "Time series to table" 변환을 사용하면, 이러한 데이터가 테이블 형식으로 변경되어, 각 시계열이 별도의 열이 되고 각 시간 포인트가 행으로 표시되는 테이블로 만들 수 있다.
Filter by name : 이쪽은 사실 이름만 봐도 느낌이 올것이라고 생각한다. 말 그대로 컬럼 name 으로 필터는 거는 것인데, query 에서 select * 대신 select Latitude, Longitude, ~~~~ 하는 것과 동일한 효과이다. 이를 통해 위도와 경도, 국가 코드 국가명, ip주소, subnet, 블랙리스트 여부를 가져왔다.
4) 여기까지만 하면 이제 geomap 에서 지도에 찍힌 marker 를 볼 수 있을 것이다. 물론 이렇게 해도 안보이면 이제 오른쪽의 설정 패널로 가서 구체적인 설정을 변경해야한다. 특히 Map layers 에서 type 을 Markers 로 지정해둔 후 Location Mode 를 Auto 로 둔다. 물론 이걸 coords 로 지정해도 무방하나 초기 설정이 Auto 로 되어있기도하고, 위도 경도 데이터가 잘 나온다는 가정하에 auto 로 설정해둬도 알아서 위도와 경도 값을 인식해 지도에 표시해주기 때문에 문제가 없다.

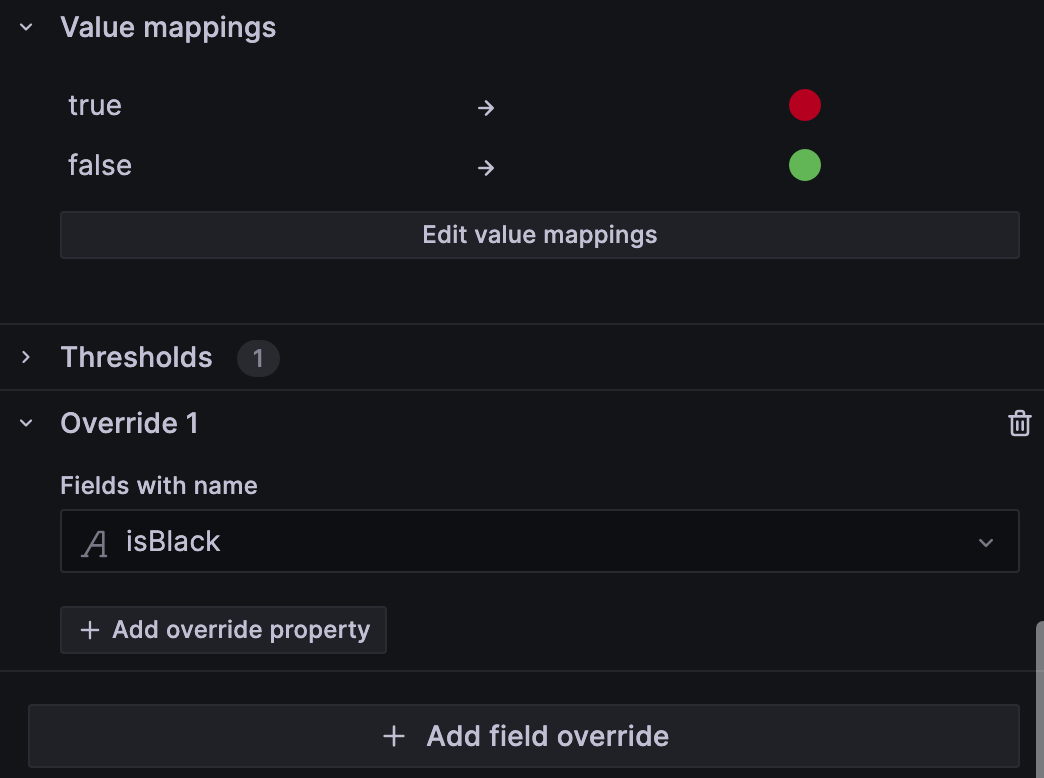
5) 다음으로 GeoMap 에서 isBlack 을 어떻게 활용하면 좋을까에 대해서 고민해보았다. 이번 플젝에서 원했던 건 단순히 map 에 marker 를 표시하는게 아닌 블랙 ip 를 표시해주는 것도 포함하기 때문이다. 이를 위해 field override 를 활용 할 수 있다. 이 기능은 특정 패널 내에서 데이터 필드의 표시 방식을 사용자가 정의할 수 있다.
예를 들어 isBlack 에 대해서 어떻게 표시해줄 수 있을 지를 정할 수 있다. 아래 사진에서는 isBlack = true 인 경우 빨간 색상을 표시하고 isBlack = false 인 대상은 초록색으로 표시하도록 만들었다.
마무리하며
이전에 "오픈스택 인스턴스 2대와 쿠버네티스를 연결해두고 뭘 하면 좋지...?" 라고 생각했었다. 가장 고민했던 '서버' 에 대한 문제는 해결했는데 이걸 '어떻게' 활용할 것인지에 대해서는 정해지지 않았었기 때문이다. 참 웃긴게 '어떻게' 사용할지 열심히 고민하지 않았지만 프로젝트에 기능이 점점 추가되면서 또 이를 어떻게 배포하고, 네트워크를 어떻게 연결할지 고민하면서 굉장히 자연스럽게 '어떻게 사용할지' 에 대한 의문이 풀리게 되었다. 심지어 이제는 인스턴스 2대로는 부족해서 3대까지 늘려놓은 상태이고, chatforyou 전용 인스턴스도 하나 만들어서 얘만 따로 거기에 배포할까...? 하는 생각도 든다.
사실 쿠버네티스에 서비스를 배포했을 때 처음부터 서로 잘 연결되고 데이터가 잘 왔다갔다 했던 것은 아니었다. 특히 prometheus 서비스를 배포했을때는 데이터를 전혀 못가져오고 연결도 안되서 정말 고생했던 기억이 있다. 또한 처음에는 자동 배포로 했었어서 모니터링 서비스들이 여기저기 배포되었었고, 이를 다시 설정해서 옮겨야 했던 문제도 있었다.
이렇게 서비스를 배포하고 연결해보면서 개발이란 단순히 '코드'만 짜는것으로 끝이 아니구나 라는 생각이 또 들었다. 개발의 시작 단계에서 서버 구성을 어떻게하고, 연결을 어떻게 할지, 어떤 데이터를 주고 받을지 '서비스 아키텍쳐'를 그리는게 얼마나 중요한지 정말 뼈져리게 느낄 수 있었다. 처음에 아키텍쳐부터 그리고 들어갔으면 내가 고생했던 시간의 반은 단축할 수 있었을 것이라고 생각한다. 동시에 '개발부터 배포까지'라는 말도안되는 목표로 고생했기에 얻은 값진 경험이라는 생각도 든다..아마도?ㅋㅋㅋㅋ
이번 포스팅에서는 못 적었지만 kurento media server, jenkins 나 sonarqube, minio 도 현재 쿠버네티스에 배포되고 있다. 여기서 jenkins 와 sonarqube 의 경우 따로 포스팅할지는 모르겠지만 적어도 minIO 의 경우 다음 '파일 업로드 기능'의 주요 골자를 차지할 예정이기에 이것과 함께 Redis 에 배포, 연결에 대해서 글을 써보려고 한다.
Reference
https://nangman14.tistory.com/81#1.%20Metrics%20Server%20%EB%94%94%EC%9E%90%EC%9D%B8-1
Kubernetes에 존재하는 Metrics Server란 무엇일까? 그리고 어떻게 해야 잘 사용할 수 있을까?
Kubernetes는 HPA(Horizontal Pod Autoscaling), VPA(Vertical Pod Autoscaling)이라는 Pod 자동 확장 기능을 제공해 필요에 따라 Pod의 수를, 혹은 리소스 자체를 자동으로 확장할 수 있는 기능을 제공하고 있습니다.
nangman14.tistory.com
https://velog.io/@junsj119/%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%EA%B4%80%EB%A0%A8
모니터링링링(prometheus, grafana, promtail, loki)
프로젝트를 진행하면서 구축한 환경 자체를 모니터링하고, 문제가 생길 경우 적절한 조치를 빠르게 취하기위해 모니터링 도입하기로 결정을 하였다. Actuator > Spring Boot에서는 어플리케이션을 모
velog.io
안정적인 운영을 완성하는 모니터링, 프로메테우스와 그라파나
메트릭이란?시계열 데이터베이스란?애너테이션으로 매트릭 수집하기멀티 컨테이너 패턴다양한 종류의 프로메테우스 익스포터PromQL 정규 표현식쿠버네티스 내에서 도메인 이름을 제공하는 CoreD
velog.io
Prometheus, Loki, Grafana를 이용한 모니터링 시스템 구축
모니터링 시스템이란, 어떤 서비스 혹은 시스템으로부터 시계열 데이터를 수집하는 시스템 입니다. 대표적인 시계열 데이터에는 CPU, 메모리 사용량 등에 대한 수치 데이터와 사용자의 활동을
rulyox.blog
'Server > Docker & Kubernetes' 카테고리의 다른 글
| 쿠버네티스 정복기 (2) ingress, ingress controller 및 externalName 사용해서 서비스 연결하기 (3) | 2024.07.31 |
|---|---|
| 쿠버네티스 kubernetes 정복기(1) 설치하기, 각종 오류 트러블슈팅, 초기화(feat.성공적) (12) | 2022.10.22 |
| Docker 개념 알아보기 : docker , docker hub, docker image (0) | 2022.09.07 |

댓글